从数据科学的可复现性到 KNIME 中如何进行测试
《自然》杂志曾在2016年刊登了一篇关于可复现性危机的文章,作者对将近一千五百名科学家进行了问卷调查,结果显示,有超过 70% 的研究人员并未能成功复制另一位科学家的实验,有一半以上的研究人员未能复制自己的实验。卡尔·波普尔(Karl Popper)也曾说过,"non-reproducible single occurrences are of no significance to science."(不可重复的单次试验对科学没有任何意义)。
数据科学也属于科学,可复现性无论对于我们自己或使用我们工作成果的他人都有着重要的意义,在 KNIME 中进行测试,能在一定程度上了解我们工作流的质量,及时发现错误,提高对最终结果的信心,以及保证我们工作的可复现性(reproducibility)。从实用的角度来�说(这也是我们《数据分析指北》的风格),在一些探索性的工作,或是一次性的工作上(one-off workflow),并不值得做专门的测试,只需要完成需要的功能,做一些简单的手动测试就可以了。但某些时候,我们会构建自己的分析模式,重复使用我们创建的某些特定节点(集),而且可能会在多个不同的 workflow 中使用它们。这个复用的逻辑和其他编程语言中的库(library)一样,对于这些抽象出来的,和具体任务无关的节点(集),我们希望它们是正确的,希望在 KNIME 版本升级以后它们能正常工作,希望它们有很好的普适性(因为我们要在多个不同的 workflow 中使用),希望在某一次对这些创建的节点(集)改进之后,没有破坏它原有的功能。在这些时候,简单的手动测试就有点困难了,我们需要的正是专门的测试。在 KNIME 中,辅助专门测试的扩展叫做 “KNIME Testing Framework”,安装之后,将会在 KNIME 主界面的 Node Repository 看到相应的节点。
安装 KNIME Testing Framework 扩展
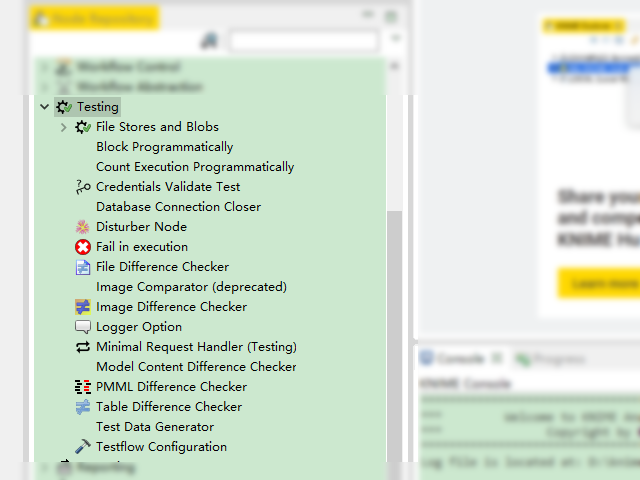
Node Repository 中展示的 KNIME Testing Framework 节点
这些节点中,有一些是通用类的辅助测试的相关节点,还有一些是具有针对性的,如文件测试相关、验证图像相关、验证模型相关等节点,这里举例介绍 Table Difference Checker 这个节点。
原始数据 A 经过我们构建的节点,生成了新的数据 B,我们脑海中真正想要的结果是 C,对于表的测试来说,其实就是在测试表 B 和表 C 是否相等。Table Difference Checker 是用来验证表 B 和表 C 中的内容是否相等的节点。对于表中的各列,也许存储着不同类型的数据,而不同类型的数据,比较方式有所差异。比如对字符型的列来说,毫无疑问 "b" 和 "b" 是相同的,但对数字类型的列来说,情况就稍微有点不一样了。考虑到计算机存储、计算有一定的误差,有时我们认为在一定误差范围内也是相等的,如果约定误差(epsilon 即 )为0.01,那么我们可以认为 1.01 与 1.015 也是相同的,也就是说,凡是满足 ,我们都认为它们是�相同的。不只是在 KNIME 中,还是在其他类型的语言中,对浮点数的测试都会有类似的问题,比如在 Python 中,会有一个叫做 assertAlmostEqual 的函数,从字面上就能猜出它和我们上面所描述的是一回事,差不多相等(almost equal)就认为是满足要求了。具体来说,在 KNIME 中需要将需要比较的两张表通过 Table Difference Checker 连接在一起,然后在这个节点的配置页面,设置对比规则就可以了,如果两张表判断不相等,那么在运行时,KNIME 的 console 就会出现错误提示,告诉我们哪里不一样,如下图所示。
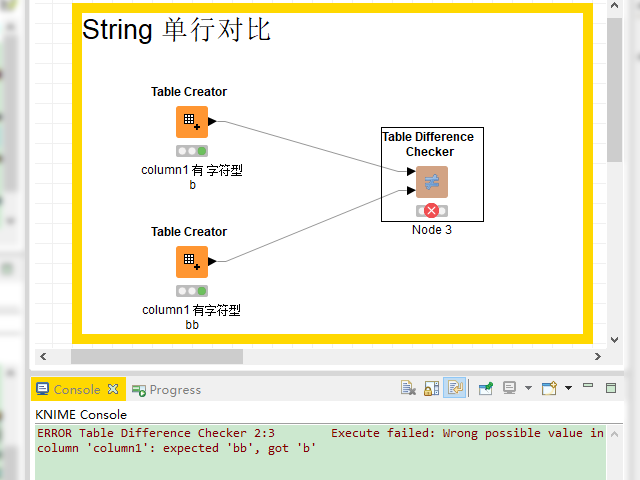
字符类型的列内容不一致时在 console 会出现错误提示
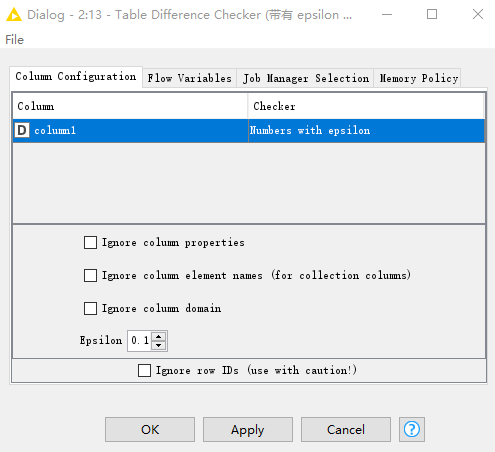
数字类型的列设置带有精度的比较方法
最后强调一下,虽然这里讲了在 KNIME 中如何进行测试,但并不是什么时候都需要测试的。文章开始时提到,一些抽象出来的节点(集)需要测试,但什么时候去测试这些抽象出来的节点(集)又是另外一个问题。我个人的建议是不要在项目、工作流设计的早期引入测试框架,因为毕竟大脑有限,在还没有设计完成时,就关心节点(集)的测试是一种过度工程。高德纳(Donald Knuth)有一句名言,premature optimization is the root of all evil(过早优化是万恶之源),也是同样的意思。垠神在编程��的智慧 一文里面关于防止过度工程的描述令我深以为然:
世界上有两种“没有bug”的代码。一种是“没有明显的bug的代码”,另一种是“明显没有bug的代码”。第一种情况,由于代码复杂不堪,加上很多测试,各种coverage,貌似测试都通过了,所以就认为代码是正确的。第二种情况,由于代码简单直接,就算没写很多测试,你一眼看去就知道它不可能有bug。你喜欢哪一种“没有bug”的代码呢? 根据这些,我总结出来的防止过度工程的原则如下:
- 先把眼前的问题解决掉,解决好,再考虑将来的扩展问题。
- 先写出可用的代码,反复推敲,再考虑是否需要重用的问题。
- 先写出可用,简单,明显没有bug的代码,再考虑测试的问题。
数据科学中也别无二致。
作业
整体上来说,这些节点的功能都相对比较简单,只需要实验一下就可以完全明白是怎么回事。列出一个试验 Table Difference Checker 功能的工作流供参考。

Table Difference Checker功能试验